
组里有一套Python Graphite已经为组里无数的服务提供了稳定的指标存储和查询服务,但是随着业务发展,老将已经力不从心,是时候该折腾折腾了。
现状
在数年的运行过程中出现过如下令人抓狂的问题:
- 数据点丢失
- 数据点落盘延迟严重
- 查询慢··慢··慢··
- 扩容时折腾环境让人抓破脑壳
而解决这些问题的方法就是无尽的扩容,到折腾之前集群有3个carbon-relay,16组carbon-cache + graphite-web,1个聚合所有节点查询的graphite-web。不利于维护且每次扩容的时候准备运行环境也非常蛋疼。所以借机器下线的机会升级一下这套指标服务。
简单说说graphite
graphite提供了几种不同的角色,分别负责不同的功能,提供不同的服务。
Graphite-Web
提供了一套render api用来查询指标,也支持非常丰富的函数比如avg/sum/alias等等,Grafana也是通过这个接口来进行指标的查询的。
提供了渲染图像的接口,Seyren是借助这些API完成的图像绘制。
同样他也提供了一套GUI来绘制图像,但是,几乎不用。
它通过cache暴露出的查询接口来查询在内存中的数据,也会直接读取*.wsp文件来完成指标的查询。
Carbon
carbon-relay
和它的名字一样,它用于「中继」,将carbon-cache和push指标的程序分离开。如果你有很多cache,那么就可以通过relay-rules将指标发送至不同的cache。像下面这样:
1
2
3
4
5
6
7
8
9
10
11
[app-a]
pattern = ^appa\..+
destinations = graphite-a:2006
[app-b]
pattern = ^appb\..+
destinations = graphite-b:2006
[default]
default = true
destinations = graphite-c:2006
carbon-cache
cache是整套集群的核心了,它负责收集指标并完成持久化存储。它支持通过TCP,UDP,pickle来上报指标,pickle`是graphite自定义的协议,可以一下发一坨指标到graphite。
cache会将指标暂时放到内存中,在达到一定条件会把这些指标写到磁盘上,这些指标以*.wsp格式存储,每一个指标都是一个wsp文件,它是一种固定大小的数据库,他的数据结构如下:
| WhisperFile | Header,Data | ||
|---|---|---|---|
| Header | Metadata,ArchiveInfo+ | ||
| Metadata | aggregationType,maxRetention,xFilesFactor,archiveCount | ||
| ArchiveInfo | Offset,SecondsPerPoint,Points | ||
| Data | Archive+ | ||
| Archive | Point+ | ||
| Point |
升级or吃螃蟹
Mentor赏了一块SSD,这比HDD简直是质的飞跃,wsp是无数个小文件,HDD对这些小文件非常力不从心,更何况是被虐待了多年的HDD。
Python Graphite
这种方法是最利于维护的,因为组里积累了很多graphite的维护经验,但是下面几个问题实力劝退了
- python环境难以维护,即使有虚拟环境的加持,第一次折腾的时候还是给整自闭了
- graphite-web性能满足不了需求,在众多面板中有几个面板要求聚合n个节点中的n个指标,数据量大且聚合函数复杂。
go-graphite
有一批热心网友用go实现了一套完整的graphite集群,提供了carbon-relay-ng/go-carbon/carbon-api,需要的功能基本也都提供了,部署方便,没那么多环境问题,而且据说性能拔群,不如做第一批吃螃蟹的人 lol~~
简单说说go-graphite
相关的项目如下:
https://github.com/grafana/carbon-relay-ng
https://github.com/go-graphite/carbonapi
https://github.com/go-graphite/go-carbon
和原汁原味的Graphite一样,go- graphite也提供了不同的角色。
carbon-relay-ng
看名字就知道它是个relay,它支持web页进行可视化的配置(经实测不怎么好用,在上面改配置有可能导致这个relay挂掉,所以还是老老实实用配置文件吧)。它可以通过三种协议来接收指标并最终通过某一种协议给后端存储服务发送指标。同样也提供了丰富的性能指标供参考。[Grafana Dashboard Template](https://grafana.com/grafana/dashboards/338-carbon-relay-ng/
go-carbon
它实现了基于whisper的后端存储服务,同样它也支持三种不同的协议,和python carbon不同的是,它提供的查询接口可以同时查询内存和硬盘中的数据。一个程序承担了读+写,有利有弊。之前有两个程序分别负责读写,现在如果go-carbon不幸身亡了那么,不能写的同时也就不能读了。
carbonapi
carbonapi提供了一批api,旨在替代graphite-web的功能,但是它只提供了查询接口,并没有提供web ui,所以访问它的的根路径时你会看到如下内容,是的,这很restful。
1
2
3
4
5
6
7
8
9
10
supported requests:
/functions/
/info/?target=
/lb_check/
/metrics/find/?query=
/render/?target=
/tags/autoComplete/tags/
/tags/autoComplete/values/
/version/
部署及配置
相比Python痛苦的依赖管理,go就香的很了,而且三个项目都提供了Makefile,一个make即可打出可执行文件,爽!接下来简单说一说部署以及使用过程中遇到的问题。
数据点不连续
这个是个非常头疼的问题,我们使用了jmxtrans来抓取很多程序的指标并发送给graphite,起初在测试环境以为是jmxtrans掉链子了,非常痛苦的把jmxtrans升级了在测试环境点就连续了,也没细查。上线以后点不连续的情况依然存在,这时候开始考虑relay的问题。查看relay日志发现大量连接关闭的信息:
1
2023-01-08 01:50:37.695 [WARNING] plain handler for 10.x.x.x:45638 returned: read tcp 10.x.x.x:2003->10.x.x.x:45638: use of closed network connection. closing conn
看来是relay把空闲的连接关闭了,但是jmxtrans并不知道,所以还是尝试用已经关掉的连接发指标。而且jmxtrans使用的是长连接…好吧,那就不让relay自己关连接了。
1
2
# close inbound plaintext connections if they've been idle for this long ("0s" to disable)
plain_read_timeout = "0s"
跑了一宿,发现情况缓解,但是点还是会时不时出现不连续的情况,这次连carbon自己的指标都不再连续了,那大概率就是carbon自己的问题了。
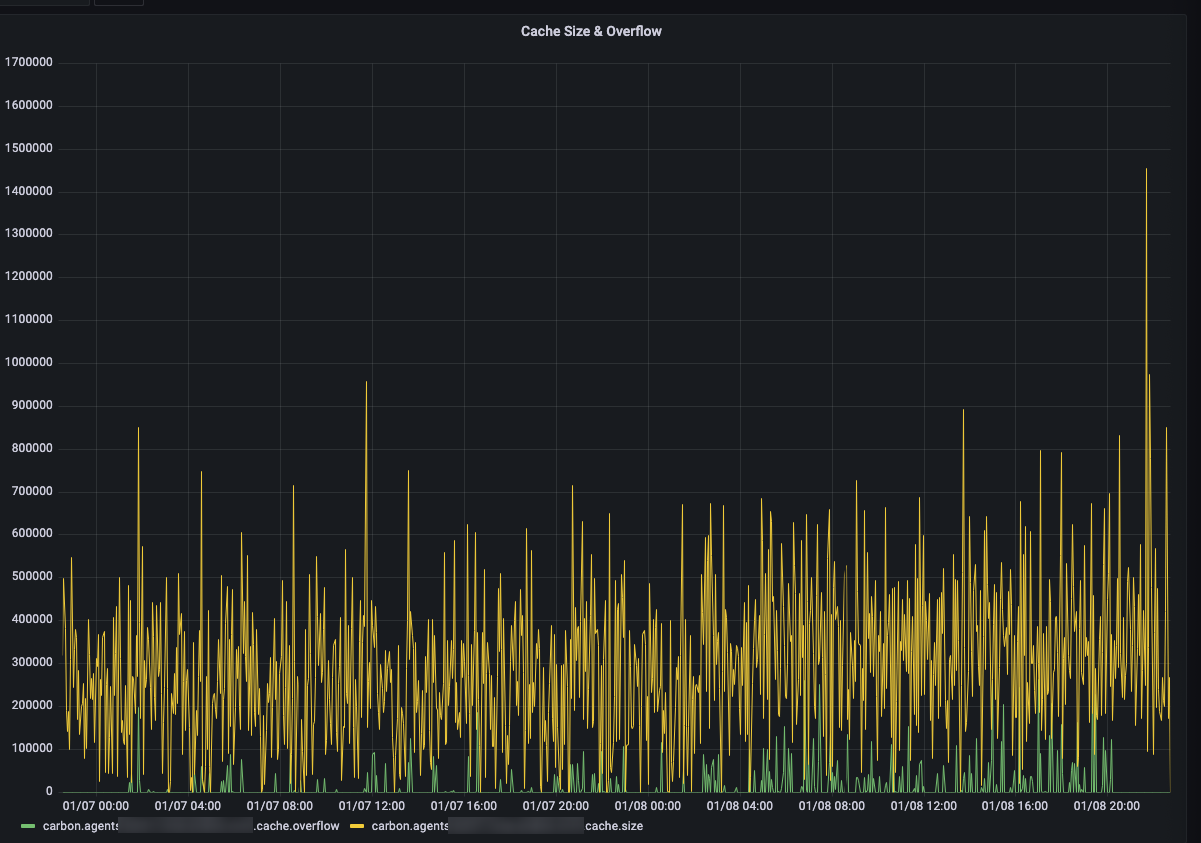
如上图,有一段时间绿色的线不再是0了,代表cache的队列存在溢出,此时carbon会丢弃掉数据点,这也就是为什么数据点不连续。carbon提供了对应的配置,粗暴的调大它即可。
1
2
3
[cache]
# Limit of in-memory stored points (not metrics)
max-size = 50000000
没法渲染图片了
大多时候我们都会使用Grafana来可视化这些数据点,但是!Seyren(一个graphite报警程序)它的图片恰恰是用graphite-web渲染的,好在没有影响报警的功能,还可以继续用。
ending
经过了这波折腾,查询速度肉眼可见的变快了。即使是一帮人一起查同一个dashboard也不至于导致整个集群卡住了,舒服!新集群又可以稳定的为组里的小伙伴提供指标服务了,巴适得板!